Implementing a Lock-Free Snowflake ID Generator
As a warning: I am by no means a lock-free programming expert. I did this exercise to learn more about lock-free techniques. The code I wrote may contain rookie mistakes leading to subtle bugs. If you can see any, please let me know!
To learn more on lock-free programming I decided to implement a Snowflake ID generator designed for high-concurrency.
In essence, Snowflake IDs are 64-bit integers embeding a timestamp in the
first bits (most significant bits), followed by a sequence numbers on the
last bits.
Twitter's original version includes a machine identifier
between the timestamp and the sequence number, but I decided to implement
a simpler version defined as follows:
- High 48 bits: Unix timestamp in milliseconds
- Low 16 bits: sequence number from 0 to 65535 (0xffff)
(This is similar to the version Mastodon uses.)
Snowflake IDs have properties that make them interesting to implement in a thread-safe manner. They must be unique and generated in a strict increasing order among workers. That means it's necessary to keep an internal state and protect it from non-serialized access causing possible corruption.
Mutex version
Here is a simple locking version using a mutex. It will serve as a comparison basis and illustrates the Snowflake generation method.
type IDGen struct {
mu sync.Mutex
ts int64 // Last timestamp in use
seq int64 // Last sequence number for that timestamp
}
This function ensures serialized access thanks to the mutex. While holding the lock, we can handle both the timestamp update and the sequence update logic in one conceptual atomic operation. Easy. We won't have such luxury with the lock-free version.
func (g *IDGen) NewID() int64 {
ts := time.Now().UnixMilli()
g.mu.Lock()
// Reset seq and ts if timestamp has gone forward
if ts > g.ts {
g.seq = 0
g.ts = ts
}
seq := g.seq
g.seq++
g.mu.Unlock()
// This is to be rigorous.
// My machine takes 25ns to generate a new ID, which is not
// fast enough to hit 65535 under a millisecond (40k IDs/ms).
if seq > 0xffff {
return -1
}
// High 48 bits = timestamp, Low 16 bits = seq
id := (ts << 16) | seq
return id
}
Is it fast?
On my machine (Intel(R) Core(TM) i7-1255U set to performance mode)
it takes ~35 ns consistently when there is no contention.
It's a 10 ns penalty compared to
the code without sync mechanism (not thread safe) which takes 25 ns.
Lock-Free Version
This version gets rid of locking by using two atomic instructions in lieu of the mutex Lock/Unlock:
-
AddInt64(*v, delta)sets*v += deltaand returns the incremented value. -
CompareAndSwapInt64(*v, old, new)sets*v = new, provided that*v == oldholds true when performing the operation, i.e., no other thread updated*vin the meanwhile.
With a lock-free version it seemed too difficult to update two
variables—timestamp and sequence number— in a consistent
manner with atomic instructions. So I operate on one id
variable, since it encodes all information we need anyway.
type IDGen struct {
id int64 // encodes last ts + last seq
}
Remarks on the following code
Last timestamp is retrievable by doing id >> 16.
Incrementing the entire ID is equivalent to incrementing only the low bits (sequence number) because
we won't go beyond to seq=0xffff. That is, we can use AddInt64 directly on the last ID.
Since CompareAndSwapInt64(*v, old, new) can fail,
thus the need for a retry loop.
It'assumed that the clock giving time only moves forward.
Now, let's see some code.
func (g *IDGen) NewID() int64 {
for {
ts := time.Now().UnixMilli()
candidateID := atomic.AddInt64(&g.id, 1)
if ts == candidateID>>16 {
// Got new incremented ID during the same ms, great, we're done!
return candidateID
}
// Timestamp has changed since last generation.
// We must reset the ID with a new ts and seq=0
// If no other thread touched g.id, it should be
// equals to candidateID returned by AddInt64.
if atomic.CompareAndSwapInt64(&g.id, candidateID, ts<<16) {
// Reset successful, we can return the new ID
// There is no need to OR anything, because seq=0
return ts << 16
}
// Not successful... It seems that another thread touched g.id
// before we were able to update it. We need to retry.
}
}
Is it fast?
When there is no contention, this lock-free version is almost as fast as the one-threaded version: 29 ns (mutex version is 35 ns, one-threaded version is 25 ns.)
Mutex vs. lock-free in case of high concurrency
Let's get things more interesting, now.
The point of lock-free algorithms is to perform well when in a high-concurrency context, right? So let's test the two different versions that way, expecting a pretty high contention.
For each run, c workers generates 10,000 IDs
concurrently. I ran the benchmark 1000 times and got the average
time in microseconds. I let the CPU cool down between each version.
Lower is better.
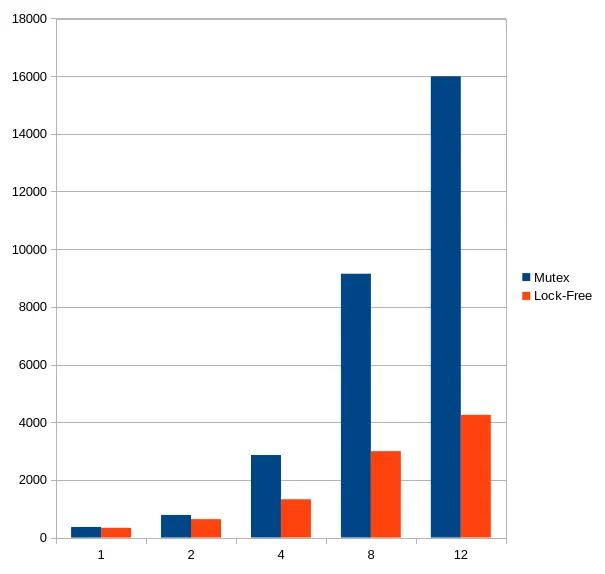
Table: (nanoseconds)
- c=1. Mutex: 366,450 - Lock-Free: 335,620
- c=2. Mutex: 781,993 - Lock-Free: 635,977
- c=4. Mutex: 2,859,663 - Lock-Free: 1,326,273
- c=8. Mutex: 9,149,252 - Lock-Free: 2,994,351
- c=12. Mutex: 15,996,348 - Lock-Free: 4,253,456
When the concurrency level is low, the two versions perform much in the same way. Substancial differences stand out when the concurrency level is 4 and more, when contention is believed to be very high. At this level, the mutex version just wallows.
I didn't go beyond 12 workers, my machine does not have more than 12 cores.
Conclusion
If the code were on a cold or warm path and contention were expected to be close to 0 most of the time, then I'd see no reason to look for anything else. Modern mutexes (futexes) are decently fast. Remember: the penalty here is only 10 nanoseconds when there is no contention. The lock-free version is hard to get it right, and to be honnest I'm not even sure I succeeded in having handled all subtle corner cases in my code, and I had to make some assumptions (time only goes forward, it's not possible to overflow the 16 low bits).
But, it was a fun exercise.